


小千今天分享的這篇spark筆試題是sparkSQL的優化器catalyst,本質上它就是一個SQL查詢的優化器,大家了解了它之后基本就能了解其他的SQL處理引擎的優化原理了。
*SQL優化器核心執行策略主要分為兩個大的方向:基于規則優化(RBO)以及基于代價優化(CBO),基于規則優化是一種經驗式、啟發式地優化思路,更多地依靠前輩總結出來的優化規則,簡單易行且能夠覆蓋到大部分優化邏輯,但是對于核心優化算子Join卻顯得有點力不從心。舉個簡單的例子,兩個表執行Join到底應該使用BroadcastHashJoin 還是SortMergeJoin?當前SparkSQL的方式是通過手工設定參數來確定,如果一個表的數據量小于這個值就使用BroadcastHashJoin,但是這種方案顯得很不優雅,很不靈活。基于代價優化就是為了解決這類問題,它會針對每個Join評估當前兩張表使用每種Join策略的代價,根據代價估算確定一種代價最小的方案。
*我們這里主要說明基于規則的優化,略提一下CBO
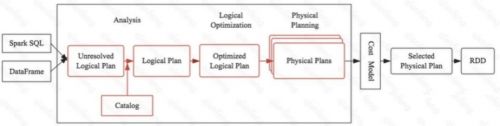
如上圖是一個SQL經過優化器的最終生成物理查詢計劃的留存,紅色部分是我們要重點說明的內容。大 家思考我們寫的一個SQL最終如何在Spark引擎中轉換成具體的代碼執行的。任何一個優化器工作原理都大同小異:SQL語句首先通過Parser模塊被解析為語法樹,此棵樹稱為Unresolved Logical Plan; Unresolved Logical Plan通過Analyzer模塊借助于數據元數據解析為Logical Plan;此時再通過各種基于規則的優化策略進行深入優化,得到Optimized Logical Plan;優化后的邏輯執行計劃依然是邏輯的,并不能被Spark系統理解,此時需要將此邏輯執行計劃轉換為Physical Plan;為了更好的對整個過程進行理解,下文通過一個簡單示例進行解釋。
Parser
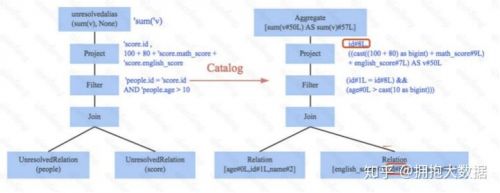
Parser簡單來說是將SQL字符串切分成一個一個Token,再根據一定語義規則解析為一棵語法樹。Parser模塊目前基本都使用第三方類庫 ANTLR 進行實現,比如Hive、 Presto、SparkSQL等。下圖是一個示例性的SQL語句(有兩張表,其中people表主要存儲用戶基本信息,score表存儲用戶 的各種成績),通過Parser解析后的AST語法樹如下圖所示:

Analyzer
通過解析后的邏輯執行計劃基本有了?架,但是系統并不知道score、sum這些都是些什么?,此 時需要基本的元數據信息來表達這些詞素,最重要的元數據信息主要包括兩部分:表的Scheme和 基本函數信息,表的scheme主要包括表的基本定義(列名、數據類型)、表的數據格式(Json、Text)、表的物理位置等,基本函數信息主要指類信息。
Analyzer會再次遍歷整個語法樹,對樹上的每個節點進行數據類型綁定以及函數綁定,比如people 詞素會根據元數據表信息解析為包含age、id以及name三列的表,people.age會被解析為數據類型 為int的變量,sum會被解析為特定的聚合函數,如下圖所示:
Optimizer
優化器是整個Catalyst的核心,上文提到優化器分為基于規則優化和基于代價優化兩種,此處只介 紹基于規則的優化策略,基于規則的優化策略實際上就是對語法樹進行一次遍歷,模式匹配能夠滿 足特定規則的節點,再進行相應的等價轉換。因此,基于規則優化說到底就是一棵樹等價地轉換為 另一棵樹。SQL中經典的優化規則有很多,下文結合示例介紹三種比較常?的規則:謂詞下推(Predicate Pushdown)、常量累加(Constant Folding)和列值裁剪(Column Pruning)
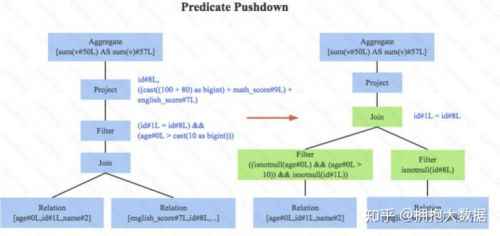
1.謂詞下推, 下圖左邊是經過Analyzer解析后的語法樹,語法樹中兩個表先做join,之后再使用age>10對結果進行過濾。大家知道join算子通常是一個非常耗時的算子,耗時多少一般取決于參與join的兩個表的大小,如果能夠減少參與join兩表的大小,就可以大大降低join算子所需 時間。謂詞下推就是這樣一種功能,它會將過濾操作下推到join之前進行,下圖中過濾條件age>0以及id!=null兩個條件就分別下推到了join之前。這樣,系統在掃描數據的時候就對數據 進行了過濾,參與join的數據量將會得到顯著的減少,join耗時必然也會降低。

2.常量累加,如下圖。 常量累加其實很簡單,就是 x+(1+2) -> x+3 這樣的規則,雖然是一個很小的改動,但是意義巨大。示例如果沒有進行優化的話,每一條結果都需要執行一次100+80的操作,然后再與變量math_score以及english_score相加,而優化后就不需要再執行100+80操作。
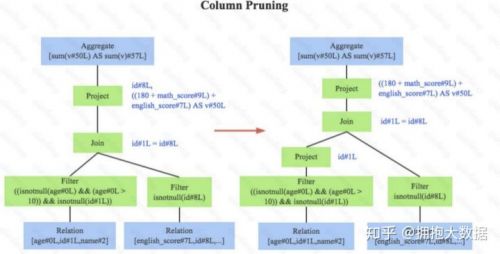
3.列值裁剪,如下圖。這是一個經典的規則,示例中對于people表來說,并不需要掃描它的所有列值,而只需要列值id,所以在掃描people之后需要將其他列進行裁剪,只留下列id。這個 優化一方面大幅度減少了網絡、內存數據量消耗,另一方面對于列存數據庫(Parquet)來說 大大提高了掃描效率
物理計劃
經過上述步驟,邏輯執行計劃已經得到了比較完善的優化,然而,邏輯執行計劃依然沒辦法真正執行,他們只是邏輯上可行,實際上Spark并不知道如何去執行這個東?。比如Join只是一個抽象概 念,代表兩個表根據相同的id進行合并,然而具體怎么實現這個合并,邏輯執行計劃并沒有說明。
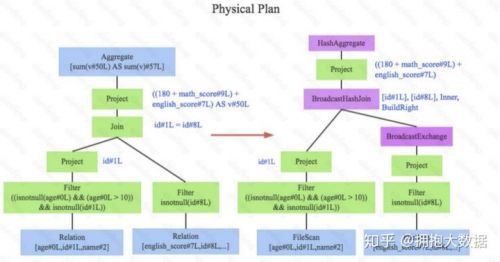
此時就需要將邏輯執行計劃轉換為物理執行計劃,將邏輯上可行的執行計劃變為Spark可以真正執 行的計劃。比如Join算子,Spark根據不同場景為該算子制定了不同的算法策略,有BroadcastHashJoin、ShuffleHashJoin以及SortMergeJoin等(可以將Join理解為一個接口, BroadcastHashJoin是其中一個具體實現),物理執行計劃實際上就是在這些具體實現中挑選一個耗時最小的算法實現,這個過程涉及到基于代價優化(CBO)策略,所謂基于代價 , 是因為物理執行計劃的每一個節點都是有執行代價的,這個代價主要分為兩部分
第一部分:該執行節點對數據集的影響,或者說該節點輸出數據集的大小與分布(需要去采集)
第二部分:該執行節點操作算子的代價(相對固定,可用規則來描述)
在SQL 執行之前會根據代價估算確定一種代價最小的方案來執行。我們這里以Join為例子做個簡單說明
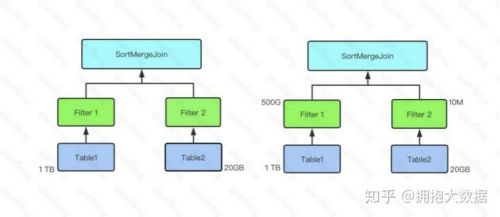
*在 Spark SQL 中 ,Join 可 分 為 Shuffle based Join 和 BroadcastJoin 。 Shuffle basedJoin 需要引入 Shuffle,代價相對較高。BroadcastJoin 無須 Join,但要求至少有一張表足夠小,能通過 Spark 的 Broadcast 機制廣播到每個 Executor 中。
*在不開啟 CBO 中,Spark SQL 通過 spark.sql.autoBroadcastJoinThreshold 判斷是否啟用BroadcastJoin。其默認值為 10485760 即 10 MB。并且該判斷基于參與 Join 的表的原始大小。
*在下圖示例中,Table 1 大小為 1 TB,Table 2 大小為 20 GB,因此在對二者進行 join 時,由于二者都遠大于自動 BroatcastJoin 的閾值,因此 Spark SQL 在未開啟 CBO 時選用 SortMergeJoin 對二者進行 Join。
*而開啟 CBO 后,由于 Table 1 經過 Filter 1 后結果集大小為 500 GB,Table 2 經過 Filter 2后結果集大小為 10 MB 低于自動 BroatcastJoin 閾值,因此 Spark SQL 選用 BroadcastJoin。
學習大數據開發,可以參考千鋒大數據培訓班提供的大數據學習路線,千鋒大數據培訓機構的學習路線提供完整的大數據開發知識體系,內容包含Linux&&Hadoop生態體系、大數據計算框架體系、云計算體系、機器學習&&深度學習。根據千鋒大數據培訓班提供的大數據學習路線圖可以讓你對學習大數據需要掌握的知識有個清晰的了解,并快速入門大數據開發。想要獲取免費的大數據學習資料可以添加我們的大數據技術交流qq群:857910996,加群找管理領取即可,有任何大數據相關問題也可以加群解決,等你來哦~~















 京公網安備 11010802030320號
京公網安備 11010802030320號